Why “Stages of Mastery” Matter (and Why the 10,000-Hour Rule Is Misleading)
The “10,000-hour rule” has done a fantastic job of marketing the idea of mastery, but it has also done a terrible job of explaining how it actually works. It suggests that time is the primary ingredient—that if you simply pour enough hours into a bucket, expertise will eventually spill out.
But we all know the person who has been driving for 20 years (far more than 10,000 hours) and is still a mediocre driver. We know the developer who has been coding for a decade but still writes messy, unscalable code. Time is not the cause of mastery; it is merely a proxy for the biological changes that happen when you practice in a specific, uncomfortable way.
Hours are just the receipt; the work that actually buys mastery is stage-aware, high-quality practice that drives neuroplasticity.
Mastery is not mystical. It is biological. When you practise with deep focus and struggle, specific neurons fire together over and over. Supporting cells in your brain (oligodendrocytes) respond by wrapping those active axons in myelin, turning slow, unreliable “dirt-road” circuits into lightning-fast “neural highways.”
That’s what “muscle memory” actually is—your nervous system upgrading its hardware so your software (your technique, decisions, style) can run faster and smoother.
Making you go from the “cognitive” stage (where you have to think about every step) to the “autonomous” stage (where you can do it in your sleep).
So if your practice is distracted, half-hearted, or misaligned with your current stage, you still rack up hours but you don’t send the right biological signals.
This article exists to offer a better model: not “just put in time,” but understand the stages of mastery and work with your biology instead of against it.
Mastery is not reserved for “naturally gifted” people. It’s a biological mechanism of the nervous system that anyone can trigger—if you understand what stage you’re in and what your brain needs at that stage.
In the next section, let’s get precise: before we stack models and biology, what do we actually mean by a “stage model” or “stages of mastery” in the first place?
What Do We Mean by “Stages of Mastery”?
At its core, “stages of mastery” is a simple idea:
Learning is not one blurry slope of “getting better.” It’s a series of recognisable phases you move through—novice → apprentice → master—in how you think, feel, act, and decide in a skill.
If mastery is a biological destination—a specific configuration of neurons and myelin—then a Stage Model is simply the map of the territory between here and there.
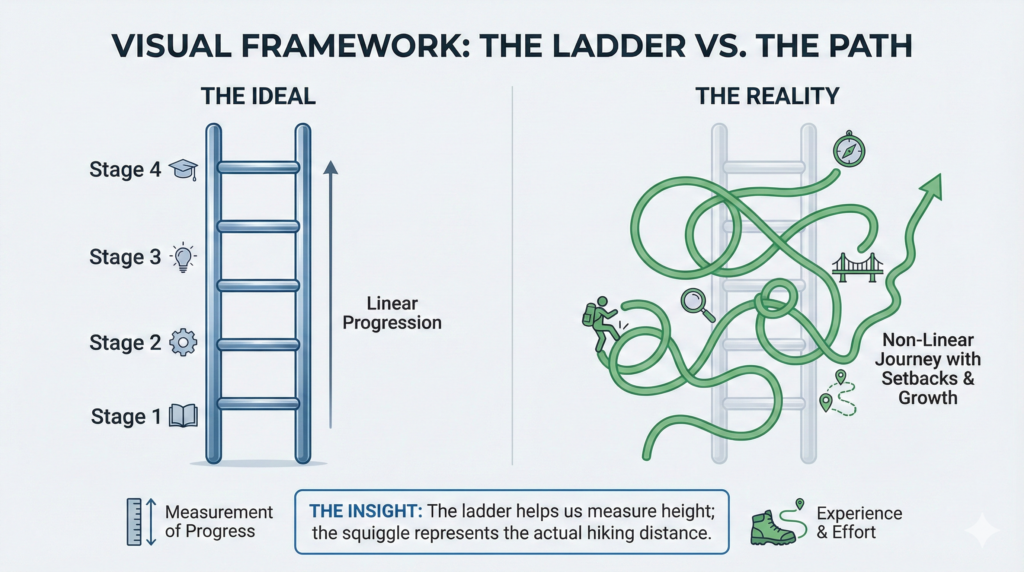
In the messy reality of learning, progress often feels chaotic. One day you feel like a genius; the next day you can’t remember basic syntax or footwork. Humans crave structure to make sense of this chaos. We build models to turn the tangled web of skill acquisition into a clean, climbable ladder.
A Stage Model is a framework that categorizes the predictable shifts in how a learner thinks, feels, and acts as they gain competence. Whether you are learning to play the violin, write code, or lead a company, you will pass through distinct phases:
Cognitive changes: Moving from “What do I do?” to “How do I do it?” to “It just happens.”
Attentional changes: Moving from tunnel vision to seeing the whole board.
Emotional changes: Moving from anxiety to frustration to boredom to quiet confidence.
However, we must start with a crucial disclaimer: Stages are useful fictions, not laws of physics.
The map is not the territory. Real learning is non-linear, recursive, and messy. You might be an “Expert” in one sub-skill (e.g., writing Python functions) but a “Novice” in another (e.g., distributed system architecture). You will frequently slide back down the ladder to fix bad habits. We use these models not because they are perfectly accurate, but because they are useful.
Benefits and Limitations of Stage Thinking
Why bother with these labels? Why not just “keep practicing”?
The Benefits:
Orientation (Panic Reduction): When you hit the “Valley of Despair” or the “Intermediate Plateau,” having a map tells you, “You aren’t broken; you are just at mile marker 10.” It normalizes the struggle.
Stage-Appropriate Practice: This is the killer app of stage models. A Novice needs rigid rules and repetition (blocked practice). An Expert needs to break rules and introduce chaos (variable practice). If you treat a Novice like an Expert, they drown. If you treat an Expert like a Novice, they stagnate.
Shared Language: It gives coaches and learners a shorthand. Instead of saying, “I’m confused about the basics but I kind of get the advanced stuff,” you can say, “I’m oscillating between Conscious Incompetence and Competence.”
The Limitations:
The “Jagged Profile”: You rarely level up all at once. You are likely a patchwork of different stages across different skills.
The Illusion of Linearity: Progress often looks like an “S-Curve” or a spiral, not a straight line. You may need to regress to a lower stage (unlearning) to move higher.
How This Guide Is Structured
We are going to dismantle and rebuild your understanding of skill acquisition using the best mental models available. Here is the roadmap:
In this guide you’ll learn:
How Fitts–Posner, Dreyfus, and the Four Stages of Competence actually fit together into one coherent map.
Why frustration, boredom, plateaus, and “I’m getting worse” phases are biologically necessary milestones, not signs that you’re broken or untalented and why flow feels great but isn’t where most learning happens,
How to move from Novice → Apprentice → Master without getting trapped in the intermediate “I’m fine” plateau where most people park for life.
How to design your own stage-aware practice system and even a custom stage model for any skill you care about—writing, coding, martial arts, entrepreneurship, content, whatever.
How to plug in AI as a Socratic tutor, smarter feedback loops, and identity work so your learning becomes faster, more honest, and more sustainable.
And most importantly show you what actually changes across stages, not just in theory, but in your:
Emotions (from anxiety to boredom to quiet confidence),
Identity (“I’m trying this” → “This is who I am”),
Practice (from volume → precision → micro-tweaks),
Environment (coaches, peers, and feedback loops).
My goal is to give you a Grand Unified Theory of Mastery—a single mental model that makes sense of all the scattered advice you’ve heard about deliberate practice, talent vs. effort, flow, discipline, “10,000 hours,” and “just be consistent.”
Think of this article as a kind of operating manual for your nervous system when it comes to skill acquisition. Not a perfect map (no model is), but a map accurate enough that you can finally stop wandering and start navigating.
If you are in a rush to diagnose yourself, skip to the “Canonical Stage Models” section below. If you want to understand the source code of human potential, keep reading.
Instead of asking “How many hours until I’m good?”, you’ll be able to ask “Which stage am I in, and what does this stage need from me to evolve?”
The Map of the Territory – Canonical Models of Skill Acquisition and Integrating the Three Great Models
If you search for “stages of learning,” you will likely find a fragmented landscape. Psychologists talk about Fitts & Posner. Business coaches love the Four Stages of Competence. Software engineers and nurses swear by Dreyfus. Martial artists preach Shu-Ha-Ri.
This confusion is unnecessary. These models are not competing truths; they are simply different lenses on the same biological reality. To navigate your own journey, you need a map that layers these perspectives:
Fitts & Posner describes what your brain and muscles are doing.
Dreyfus describes how your decision-making evolves.
Plus two “honourable mentions” (Shu-Ha-Ri and the S-curve).
By the end of this section, you’ll see how they fit together, when to use which, and why you don’t have to pick a religion. You can use all of them as tools aka as a single, unified operating system.
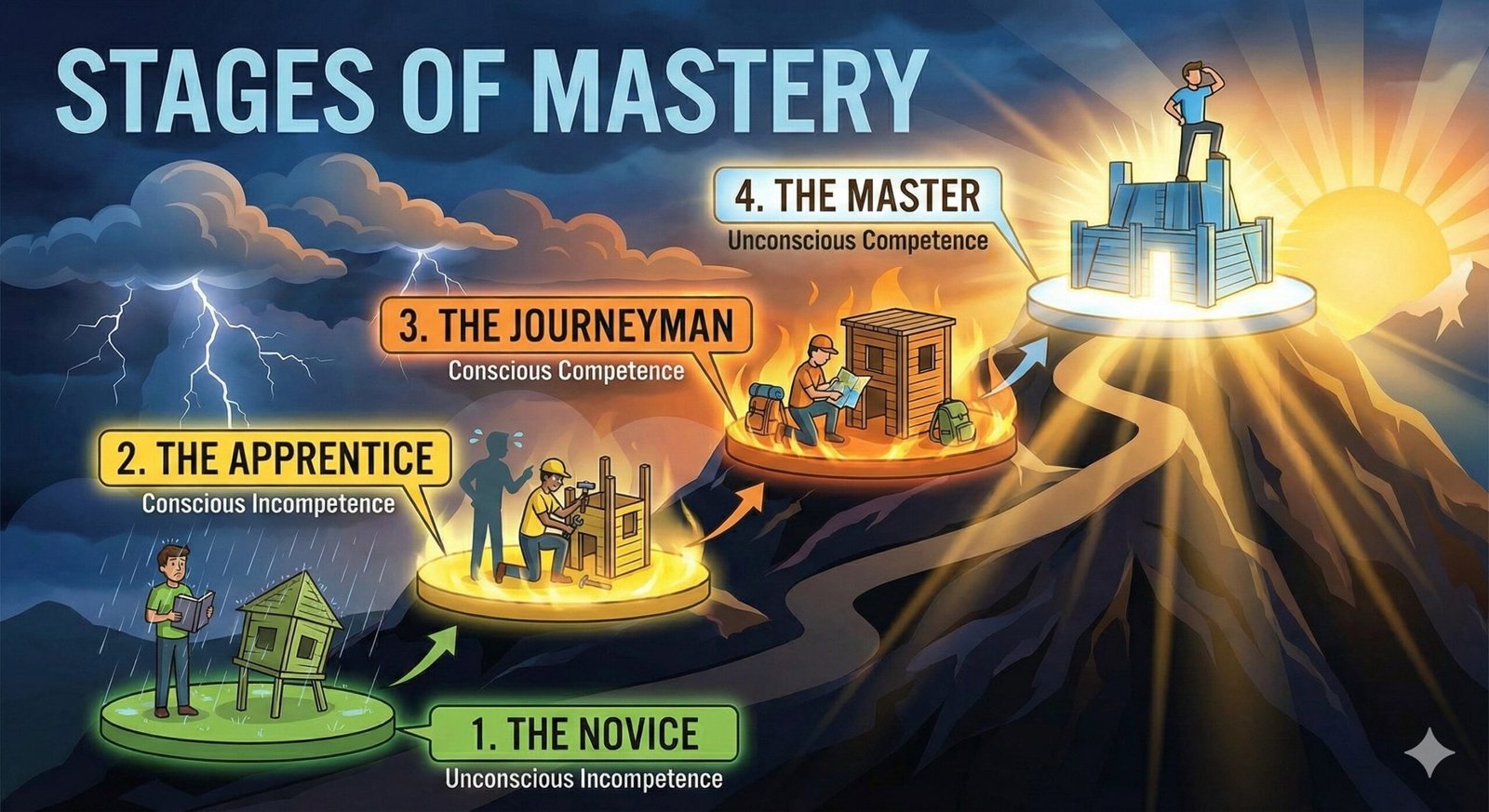
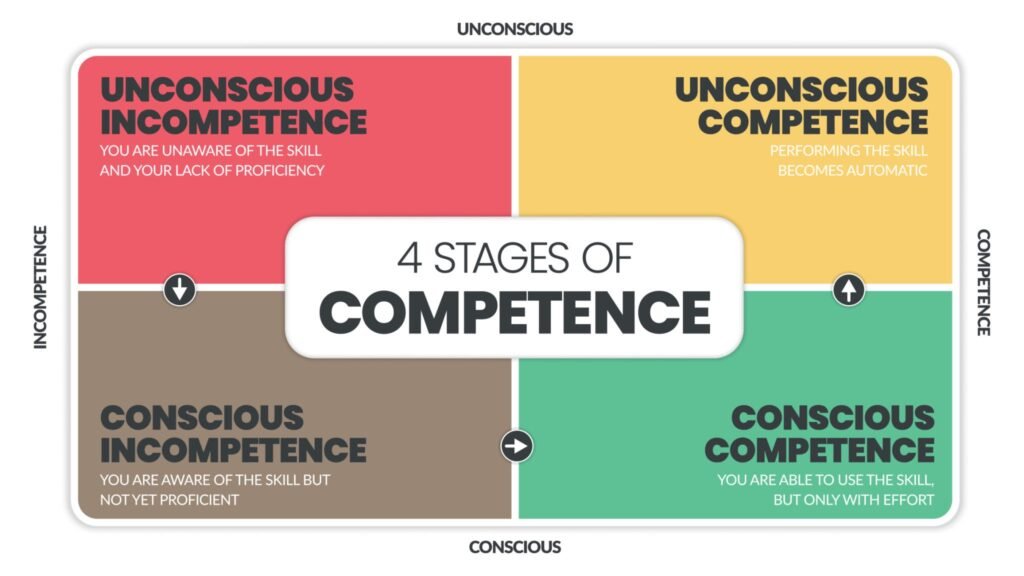
The Four Stages of Competence: From “I Don’t Know I Suck” to “I Just Do It”
This is the most famous model for a reason: it perfectly captures the emotional arc of learning. Attributed to Noel Burch in the 1970s, it tracks your awareness of your own ability.
Quick Overview
In plain language, the Four Stages of Competence also knows as The 4 stages of Mastery describe how your awareness of your skill evolves:
Unconscious Incompetence (Ignorance): You don’t know what you don’t know. You think writing a novel is “just typing.” You’re in blissful ignorance – that’s what I like to call it.
Conscious Incompetence (Pain): You realize how hard it is and you finally see the gap. Your taste exceeds your ability and You realise how bad you are. This is where the ego takes a hit which I like to call the “oh no” stage.
Conscious Competence (Effort): You can do it, but it takes 100% of your focus. You are sweating the details. So if someone distracts you, the performance falls apart.
Unconscious Competence (Mastery): The skill happens on autopilot.
Real-Life Examples Across Skills
Driving a car
Stage 1: You think “how hard can it be?”
Stage 2: First lesson. You stall, panic, oversteer.
Stage 3: You can drive, but you need silence to focus.
Stage 4: You arrive somewhere and barely remember the turns.
Writing
Stage 1: “I have good ideas, I’ll just write.”
Stage 2: You see your drafts next to good writing and cringe.
Stage 3: You can produce solid pieces, but it’s effortful.
Stage 4: You write in your voice without overthinking every sentence.
Coding
Stage 1: “I’ll learn a bit of Python and build an app this weekend.”
Stage 2: Error messages everywhere.
Stage 3: You can build features, but you’re slow and careful.
Stage 4: You think in abstractions and architecture, not just lines of code.
Martial arts / music / content creation / entrepreneurship follow the same emotional arc:
“This looks easy” → “Wow this is hard” → “I can do it if I focus” → “This is just part of who I am.”
Crucial Nuance: Many people believe “Unconscious Competence” is the finish line. It is not. It is merely the baseline for style. Once the mechanics are unconscious, you finally have the mental bandwidth to express artistry.
Strengths and Weaknesses
Best for: Beginners, emotional orientation, and explaining the “frustration phase” to students.
Weakness: It lacks nuance at the top end. It treats “Mastery” as a static state of autopilot, failing to distinguish between a “good driver” (who is unconscious but stagnant) and a Formula 1 driver (who is unconscious but constantly optimizing).
In Textbook Defination: What are the Four Stages of Competence?
Matrix diagram of 4 stages of competence into a vector chart infographic for human resource development such as Unconsciously and Consciously Incompetent, Consciously, and Unconsciously Competent.
“The Four Stages of Competence is a psychological model describing the progression of learning from ignorance to mastery. The stages are:
Unconscious Incompetence: You don’t know what you don’t know (Ignorance).
Conscious Incompetence: You are aware of your skill gap and the struggle begins (Awareness).
Conscious Competence: You can perform the skill, but it requires intense focus and effort (Learning).
Unconscious Competence: The skill is automatic and second nature, often described as ‘muscle memory’ (Mastery).”
Fitts & Posner’s Three Stages of Learning: Cognitive, Associative, Autonomous
While the Four Stages model looks at your feelings, Paul Fitts and Michael Posner (1967) looked at your cognitive load. This model is the gold standard in motor learning and neuroscience.
Overview of the Three Stages
Cognitive Stage (Verbal-Motor): You are intellectualizing the task. You have to “talk yourself through it.” Performance is erratic and full of gross errors. Your brain is lit up with activity in the Prefrontal Cortex (PFC).
Associative Stage (Motor-Sensory): The “refining” phase. You stop verbalizing and start detecting your own errors. You are associating specific cues (the sound of the engine) with specific actions (shifting gears). This is the longest stage.
Autonomous Stage (Automaticity): The skill is hardwired. Control shifts from the conscious PFC to the basal ganglia (habit center). You can perform the skill while holding a conversation.
Where the Four Stages model says “you’re consciously competent now,” Fitts–Posner says “you’ve shifted from heavy cognitive load to automatic routines.”
What’s Happening in the Brain?
This model maps directly to myelination
In the Cognitive Stage, the Prefrontal Cortex (PFC) does most of the work:
You’re verbalising steps (“elbow here, wrist like this”),
You’re burning a lot of energy,
Working memory is overloaded because it can only juggle a few chunks at once.
Over time, as you practice with focus and feedback:
Control gradually shifts from the PFC to Basal Ganglia and Cerebellum.
Movements or sequences become “chunks” instead of separate actions.
This is where myelination kicks in:
Specialised cells (oligodendrocytes) wrap active axons in myelin,
Signal speed jumps from a slow crawl (~0.5–10 m/s) to expressway speeds (up to ~150 m/s),
The result: your reactions feel instantaneous.
Cognitive Load Theory fits perfectly here:
At the start, your working memory is overloaded by too many details.
As you form schemas (chunks), each schema counts as a single “unit” in working memory.
That’s why experts can “hold” a whole situation in mind and respond smoothly, while beginners freeze.
In short: Fitts–Posner is the story of how effortful, conscious processing becomes fast, automatic execution. (AHA!)
Practical Examples in Different Domains
Coding
Cognitive: Googling syntax every 5 minutes.
Associative: You still check docs, but you know typical patterns.
Autonomous: You architect systems, write clean code, and only look things up for edge cases.
Writing
Cognitive: Forcing yourself to remember structure, rules, and frameworks.
Associative: Your drafts come out smoother, editing hurts less.
Autonomous: You write in your voice instinctively, focusing more on what you’re saying than how.
Martial arts / music / sport
Cognitive: Drilling basic techniques slowly and clumsily.
Associative: Linking techniques into combos, smoother transitions.
Autonomous: Sparring or performing at full speed without narrating each move in your head.
Strengths and Weaknesses
Best for: Sports, music, and any domain with a strong motor component where “overthinking” causes choking.
Weakness: It implies that “thinking” is bad at the final stage, which isn’t always true for knowledge work.
The Dreyfus Model of Skill Acquisition: How Experts Stop Thinking Like Beginners
Developed by Stuart and Hubert Dreyfus at UC Berkeley, this model challenges the idea that experts are just “better rule followers.” It argues the exact opposite: Novices follow rules; Experts rely on intuition.
If Fitts–Posner asks “what is your body and attention doing?”, the Dreyfus model asks, “how are you making decisions?”
The Five Stages in Plain Language
The Dreyfus brothers describe skill acquisition in five levels:
Novice: Needs rigid, context-free rules (“When X, do Y. Don’t improvise.”). Fails when the rules don’t fit the situation.
Advanced Beginner: Starts to recognize situational aspects (“Usually do Y, but if Z happens, tweak it”) but still relies on rules.
Competent: Can plan, prioritise, and take responsibility for outcomes and chooses between rules based on the situation.
Proficient: Perceives the situation holistically. No longer “chooses” a plan; the situation “elicits” the plan. (“I just felt the car sliding and corrected it.”)
Expert: Pure intuition. The distinction between the user and the tool disappears. Rational analysis is only used when intuition fails or for troubleshooting.
Where Four Stages = “how it feels” and Fitts–Posner = “what your attention is doing,” Dreyfus = “how sophisticated your judgement is.”
How Decision-Making Changes
The profound insight here is that teaching an expert to follow the rules of a novice will degrade their performance.
Novice
Follows recipes.
Little responsibility; just executes instructions.
Advanced Beginner
Still rule-based, but can adjust slightly to context.
Might recognise: “This is like that previous case, but with a twist.”
Competent
Chooses between strategies, sets goals, and accepts trade-offs.
Starts to feel genuine ownership—and stress.
Proficient
Reads the whole situation, not just isolated details.
Uses intuition to prioritise, then checks against rules.
Expert
Relies primarily on intuition: fast, context-sensitive, often subconscious.
Rules show up as a backup system for teaching or debugging.
This model is gold for understanding why good decision-making feels slow and painful in the middle, and almost magical at the top.
A master chess player does not calculate 20 moves ahead; they “see” the right move instantly (Pattern Matching) and then calculate to verify it.
Examples in Knowledge Work and Creative Fields
Developer
Novice: copy-pasting Stack Overflow solutions.
Advanced Beginner: minor tweaks and bug fixes.
Competent: implementing features end-to-end.
Proficient: designing systems and anticipating edge cases.
Expert: shaping architecture and guiding other developers’ thinking.
Writer
Novice: clings to templates and formulas.
Advanced Beginner: experiments cautiously with format and tone.
Competent: reliably produces solid pieces for a specific audience.
Proficient: shapes narrative and structure intuitively.
Expert: invents styles and becomes a reference point for others.
Entrepreneur
Novice: does everything themselves, follows generic playbooks.
Advanced Beginner: tweaks offers and processes based on early feedback.
Competent: builds some systems and hires people.
Proficient: designs strategy and culture consciously.
Expert: treats the whole business as a living system; decisions look “simple,” but they’re backed by massive experience.
Fitts & Posner vs. Dreyfus – A Comparision
“While both models describe skill acquisition, Fitts and Posner (1967) focuses on the motor/cognitive load transition (Cognitive to Autonomous), making it ideal for sports and physical skills.
The Dreyfus Model (1980) focuses on decision-making (Rule-based to Intuitive), making it better suited for professional skills like nursing, chess, or management.”
Honourable Mentions: Shu-Ha-Ri and the S-Curve
Before we unify everything, two more lenses are worth adding to your toolkit.
Shu-Ha-Ri – Copy, Break, Transcend
Shu-Ha-Ri is a Japanese framework from martial arts, often used in creative fields:
Shu (Protect/Obey): You copy the forms exactly. Zero improvisation. Trust the kata.
Ha (Detach/Digress): You start bending rules and exploring variations. You understand the “why” behind the moves.
Ri (Leave/Separate/Transcend): You internalise principles so deeply that you can create new forms. You’re no longer bound by the old structures.
This is a universal pattern. You must copy (Shu) before you can remix (Ha), and you must remix before you can invent (Ri).
Fun Fact: This is the exact thing Austin Kleon talks about in his book, “Steal Like An Artist”
You can see Shu-Ha-Ri everywhere:
In writing: imitate → adapt → invent.
In coding: follow tutorials → remix patterns → create your own architectures.
Practice playbooks (blocked vs interleaved, etc.),
Modern tools like AI tutors and simulations.
The models give you the map; the rest of the guide gives you the driving instructions.
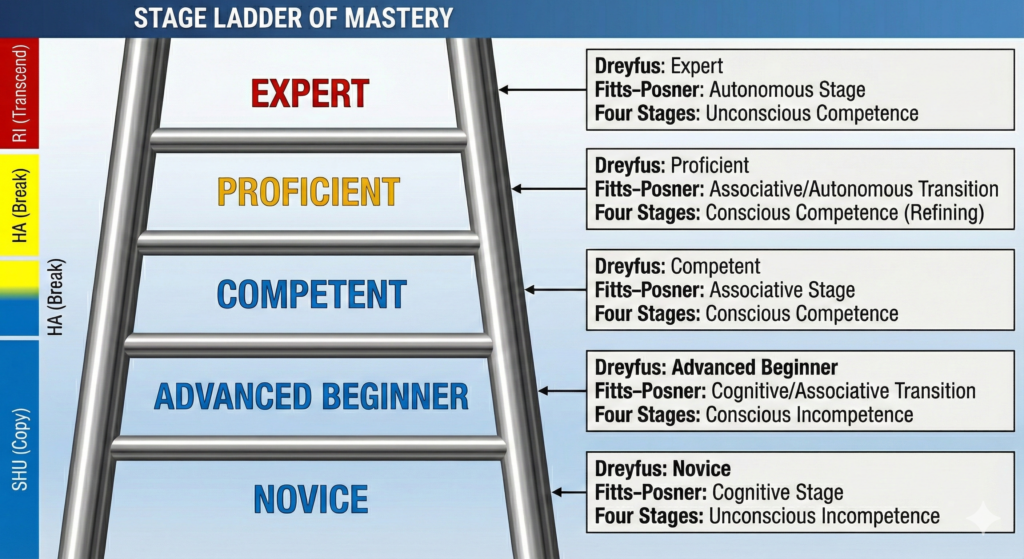
Unified Comparison: The Stage Ladder of Mastery
Let’s put everything on one ladder so you can see the overlaps at a glance.
The Unified Ladder:
Phase
Fitts & Posner (Brain/Attention)
Dreyfus (Decision Making)
4 Stages (Awareness/Feeling)
Shu-Ha-Ri
1. The Download
Cognitive
High mental effort. Verbalizing steps.
Novice
Follows rigid rules. No context.
Conscious Incompetence
“This is hard. I am bad at this.”
Shu
Obey the form.
2. The Grind
Associative
Refining movements. Detecting errors.
Competent
Planning & choosing. Emotional buy-in.
Conscious Competence
“I can do it if I focus.”
Ha
Break the rules.
3. The Flow
Autonomous
Automatic. Low brain load.
Expert
Intuitive grasp. Contextual.
Unconscious Competence
“It just happens.”
Ri
Transcend the form.
Don’t treat this as mathematically exact; treat it as a Rosetta stone that lets you translate between models.
Where They Agree (Underlying Pattern)
All these models secretly agree on a few core truths:
You start rule-based, anxious, and high-effort.
The middle is messy, frustrating, and has the highest dropout rate.
The top end is intuitive, fast, and simple on the surface, but vulnerable to plateaus if you stop challenging yourself.
The Thesis Summary
If you take nothing else from this section, remember this distinction:
Fitts & Posner explain what your body and attention do (High load → Low load).
Dreyfus explains how your judgement evolves (Rules → Intuition).
The Four Stages explain how your confidence feels (Ignorance → Pain → Flow).
Understanding this helps you diagnose yourself. If you feel “painfully aware of every mistake” (Conscious Incompetence), you know you are likely in the Cognitive/Associative transition, and the prescription is volume of reps, not more theory.
The Biology of Competence: Myelin, Neurochemistry, and Why Struggle Matters
The “10,000-Hour Rule”—popularized by Malcolm Gladwell—is catchy, but it is biologically imprecise. It suggests that mastery is a savings account where you deposit hours until you hit a magic number and “withdraw” expertise.
“Put in your hours and greatness is inevitable.”
BUT your brain does not have a built-in hour counter. In reality, “mastery” is not a measure of time; it is a measure of tissue.
If you practice a guitar chord loosely while watching Netflix, you are clocking hours, but you are not triggering biological change. You are merely reinforcing a sloppy neural circuit. Mastery requires a specific type of signal intensity to convince your nervous system to physically restructure itself.
This section explains the hardware (myelin) and the software (neurotransmitters) that make that happen.
Time vs. Tissue: Why Hours Are Just a Proxy
Let’s start by gently killing the 10,000-Hour myth.
The original research behind it (Ericsson, not Gladwell) never said, “You must do exactly 10,000 hours and you’re done.” It said something more interesting: elite performers tend to accumulate thousands of hours of a very specific type of practice—deliberate, structured, feedback-rich.
So what’s wrong with the “just put in your hours” story?
You can waste hours in low-focus, autopilot practice.
You can compress years of progress with the right kind of intensity and feedback.
Two people can both “practice” for an hour and get completely different amounts of brain change out of it.
Time doesn’t cause mastery. It’s caused by repeated, high-quality “plasticity events” in your brain.
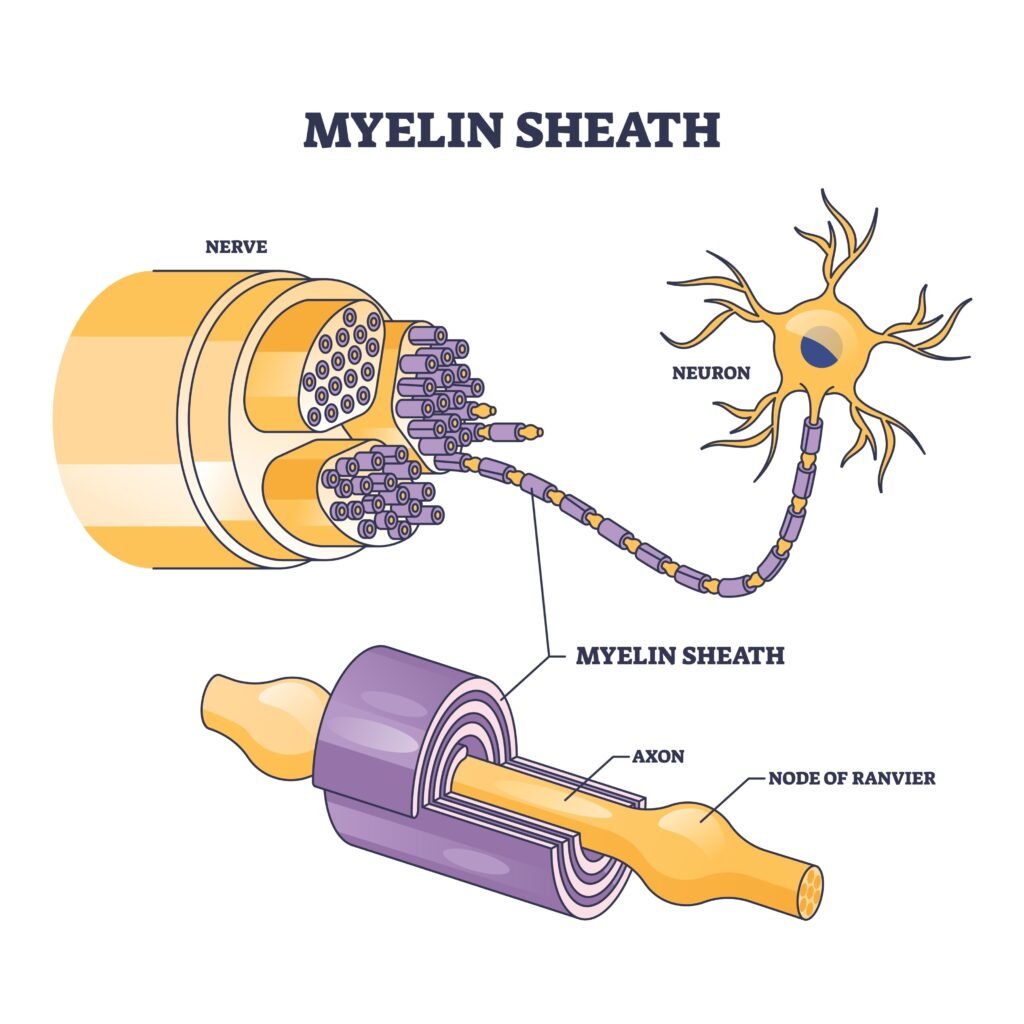
The Substrate – Oligodendrocytes and Myelin as the Hardware of Mastery
Now we zoom into the hardware.
Inside your brain and spinal cord you have oligodendrocytes (the cells that build white matter). They behave like the construction workers of mastery and their job is simple and ruthless:
“Show me which neural circuits you actually use under load, and I’ll invest in those.”
When you repeatedly fire the same neural pathways during focused practice, oligodendrocytes notice the activity and respond by wrapping those axons in myelin, a fatty insulating sheath.
Why does that matter?
A bare axon is like a dirt road—signals move, but they’re slow and leaky.
A myelinated axon is like a superhighway—fast, efficient, and reliable.
This insulation transforms how signals travel:
Unmyelinated fibres: roughly 0.5–10 metres per second
Myelinated fibres: up to ~150 metres per second
The mechanism is called saltatory conduction:
Instead of a signal crawling along the entire length of the axon,
It jumps between exposed gaps called Nodes of Ranvier,
Like a parkour runner leaping between rooftops instead of jogging through every street.
The result you feel:
Faster reaction times,
Cleaner execution,
Less conscious effort for the same action.
So when we say, “Experts are on another level,” it’s literally true: Their signal is physically traveling at 100x the speed of yours.
You cannot “out-think” myelin. You have to build it.
Your practice sessions are basically sending a funding request to oligodendrocytes:
“These circuits again. Under stress. With errors. Please reinforce.”
They don’t care about your goals, your identity, or how badly you “want it.” They only care what you actually do, repeatedly, under meaningful load.
Neurotransmitters as the Learning Gate: “Get Ready, Go, Save”
Your brain is energy-efficient—it resists change by default. To trigger the expensive process of remodeling, you must release a specific chemical cocktail that tells the brain: “This is important. Save this.”
So if myelin and oligodendrocytes are the construction crew, neurotransmitters are the project managers. They decide:
When to wake up the system,
Where to point your focus,
What to save and wire in.
Dr. Andrew Huberman and other Neuroscientists describe this as a three-stage loop your brain runs whenever you learn something new: Get Ready → Go → Keep Going.
1. Alertness (Norepinephrine) – Get Ready
Norepinephrine (also called noradrenaline) is your alertness and urgency signal.
Subjectively, it feels like:
Agitation
“Ugh, this is hard.”
That slightly anxious buzz when you’re outside your comfort zone.
This isn’t a bug; it’s your brain saying:
“Pay attention. Something important or uncertain is happening.”
If you aren’t frustrated, you likely aren’t releasing enough norepinephrine to open the gate for plasticity.
2. Focus (Acetylcholine) – Go
Acetylcholine is your attention spotlight.
It:
Narrows your focus onto specific sensory inputs or actions,
Helps tag particular circuits as “the ones we’re working on right now.”
Subjectively, it feels like:
Tunnelled attention,
Deep concentration on a tiny slice of the task,
The world shrinking down to just this rep, this phrase, this movement.
This is why trying to “multitask” your way through practice is pointless: if the spotlight is diffused, the wiring instructions are fuzzy.
3. Reward (Dopamine) – Keep Going
Dopamine is the save button for learning.
It doesn’t just show up when things feel good; it shows up in response to Reward Prediction Error (RPE):
When something goes better than expected,
Or when you finally correct an error you’ve been wrestling with.
Subjectively, it feels like:
“Aha!”
Satisfaction,
The little hit of motivation that makes you want to try again.
Each spike of dopamine basically writes a note to the system:
“This pattern we just used? That’s the one. Strengthen that.”
This is why struggle + fix + small win is so potent. Errors create tension; correcting them closes the loop and tells your brain: “Wire this version in.”
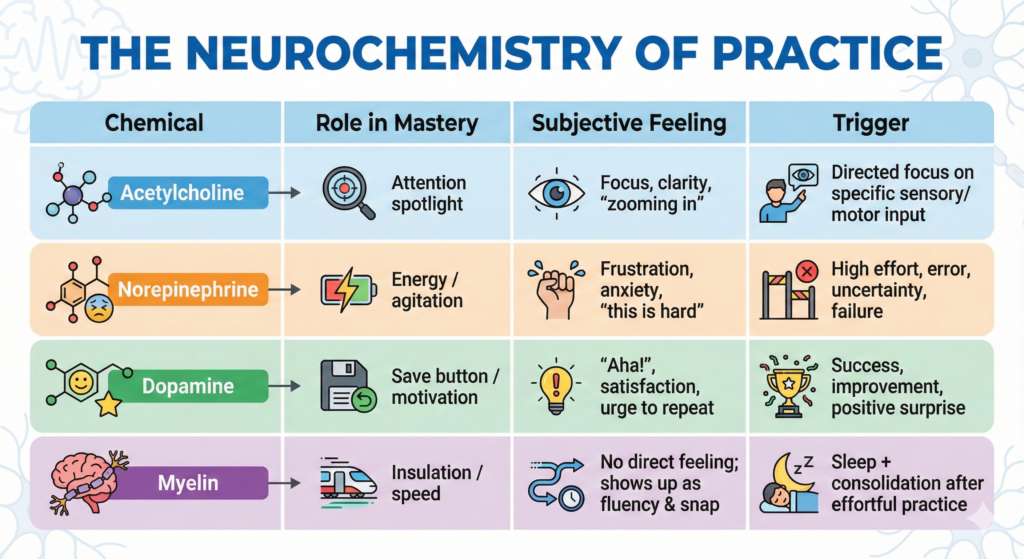
Table: The Neurochemistry of Practice
Chemical
Role in Mastery
Subjective Feeling
Trigger
Norepinephrine
The Alert
Opens the gate for plasticity.
Frustration, Agitation, Anxiety, “This is impossible.”
High effort, error, failure, strain.
Acetylcholine
The Spotlight
Marks specific neurons for change.
Focus, Clarity, narrowing of vision.
Directed attention to a specific problem.
Dopamine
The Save Button
Strengthens the connection.
Satisfaction, Motivation, “Yes!”
Success, surprise, or correcting an error.
Myelin
The Insulation
Increases speed 100x.
(No feeling)
Manifests as fluency/speed.
Sleep (consolidates the signals above).
Why Frustration, Not Flow, Is the Engine of Learning
There is a dangerous misconception that “Flow” is the best state for learning. It is not.
Flow is a state of performance. It is low-friction, high-speed execution using existing neural highways. It feels amazing, but it creates very little structural change.
Plasticity (Learning) requires friction. It requires the norepinephrine spike that comes from struggle and error.
High effort, high attention, error + correction = high plasticity.
So if your practice session feels “smooth” and “easy,” you are optimizing for performance, not learning. To move from Novice to Master, you must fall in love with the frustration. That agitation is not a sign that you are failing; it is the biological signal that your brain is ready to upgrade.
What Actually Changes Across Stages – Mind, Brain, Emotion, Practice, Environment
Models like Dreyfus and Fitts & Posner give us the labels, but they don’t capture the feeling of the metamorphosis. Moving from Novice to Master isn’t just about “knowing more.” It is a fundamental restructuring of your reality—how you see, how you feel, and who you believe you are.
When you upgrade your operating system from Windows 95 to Windows 11, the interface, speed, and capabilities change entirely. The same happens to the human “operating system” as it myelinated specific circuits.
If you zoom out on any long skill journey, the labels—Novice, Intermediate, Expert—are just chapter titles. What actually changes underneath is how your mind pays attention, how your brain is wired, how your emotions behave, how you practice, and who you surround yourself with.
Here is the phenomenology of that upgrade.
Cognition & Attention: From “Brain Hell” to “The Matrix”
At the cognitive level, the journey of mastery is a journey from rules → patterns → vibes:
At the start, you cling to rules.
In the middle, you juggle patterns.
At the top, you just… see it.
Under the hood, this is about cognitive load and chunking.
Cognitive Load and the “Chunking” Shift
For a Novice, the world is high-resolution noise. Because your brain hasn’t learned what to ignore, it treats everything as important.
That’s why day 1 of any serious skill is brain hell.
For example, you’re in a boxing class trying to remember:
stance,
guard,
chin tucked,
breathe,
jab,
cross,
pivot…
Each one feels like a separate thing. Your working memory (which can handle roughly 3–5 “chunks” at a time) gets swamped. That’s Cognitive Load Theory in action: performance collapses when the number of active elements outruns your mental bandwidth.
Novices experience:
Every note in a chord as separate.
Every line of code as a separate instruction.
Every step in a sales call as a separate mini-task.
Masters don’t have “more RAM.” They have better compression. They operate on chunks:
Guitarists feel a full chord as one unit.
Developers see common patterns (loops, conditionals, API calls) as a single “shape.”
Fighters experience combos as one fluid pattern, not six separate moves.
Chunking is simply: grouping elements that regularly appear together into a single mental unit. Over time, your brain literally recodes the task into bigger, more meaningful blocks—schemata—so you can think less and do more.
The perfect example of “Chunking” is gaming. You wait for an attack > You parry > You attack
The Prediction Horizon and Decision Speed
The second big shift and the most distinct cognitive marker of mastery is how far ahead you can see. Your prediction horizon.
Roughly:
Beginners: see one move or one second ahead.
Intermediates: see 2–3 moves ahead.
Experts: can simulate multiple futures 5–10 moves deep.
Examples:
Chess:
Beginner: “I move this piece.”
Intermediate: “If I move here, they might respond with A or B.”
Expert: runs branching trees in their head and just “knows” which lines are poison.
Combat sports:
Beginner: reacts to what’s happening now.
Intermediate: starts baiting reactions.
Expert: is playing a conversation three exchanges ahead.
Trading or content strategy:
Beginner: “This tweet / trade looks good right now.”
Intermediate: “What does this do over the next week?”
Expert: sees the second- and third-order effects months out.
Debugging / coding:
Beginner: pokes randomly.
Intermediate: narrows to a subsystem.
Expert: immediately tests the two or three most likely failure points.
The further your prediction horizon, the calmer your decisions feel. You’re not reacting; you’re surfing a wave you saw coming a long time ago.
This is why experts seem relaxed doing things that fry your brain: they’re running on autopilot for basics and spending their conscious attention on the interesting 5%.
Emotional Terrain: Anxiety, Boredom, Flow and the “Fool” Phase
Skill journeys don’t just have cognitive stages; they have emotional seasons. If you don’t recognise them, you’ll keep misdiagnosing normal weather as a personal failure.
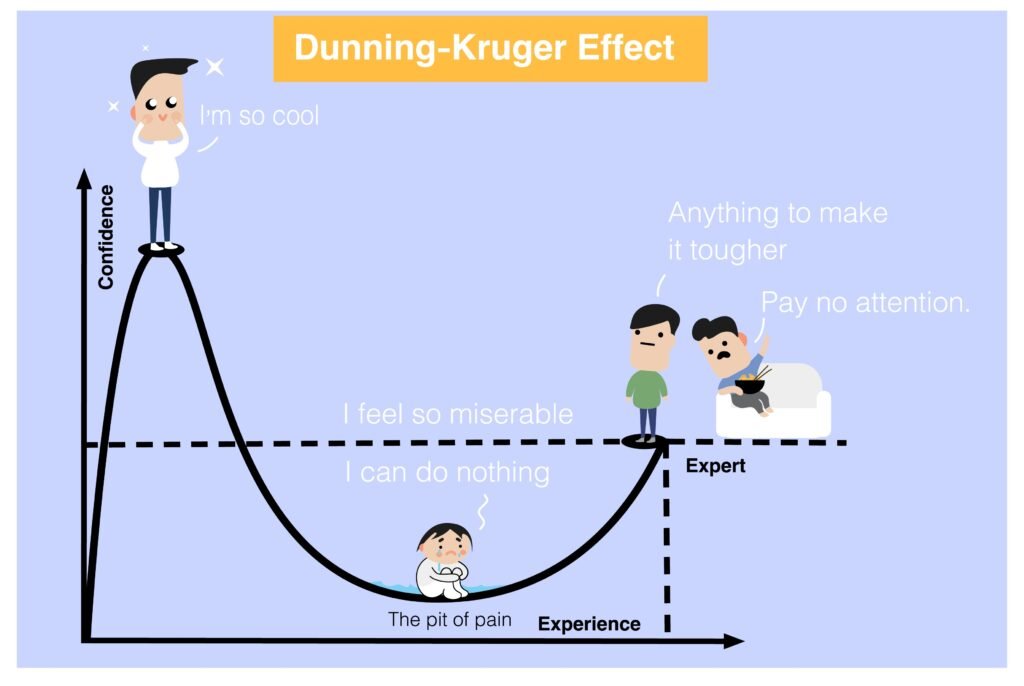
The Honeymoon, the “I Suck” Cliff, and the Intermediate Blues
Early on, the emotional arc often looks like this:
Honeymoon:
Everything is exciting.
You’re obsessed with gear, tutorials, possibilities.
You watch experts and imagine yourself there in 6–12 months.
“I Suck” Cliff:
Reality lands.
You now know enough to see how bad you are.
Shame, confusion, self-doubt show up: “Why is this so hard for me?”
Intermediate Blues:
You’re no longer terrible.
You’re also not noticeably getting better week to week.
This is the land of, “I’m okay, but is this it?” and silent quitting.
Nothing is wrong with you here. You’re just experiencing the emotional side of neural reorganisation: your brain is building new representations, and your ego is catching up.
Flow Windows Across Stages
Flow—the state where challenge and skill are balanced, time disappears, and things feel effortless—is not evenly distributed across the journey.
At the beginning, cognitive load is too high. You’re juggling too many variables to enter deep flow reliably.
In the middle, once you’ve built some chunks but still have meaningful challenge, flow is most common.
At elite levels, flow becomes thinner but deeper:
Harder to access without deliberate challenge.
But when you do hit it, it feels profound—like time has stopped and you’re watching yourself perform.
Understanding this matters because:
You shouldn’t expect constant flow as a beginner. You should expect intermittent sparks of it as a reward for structured struggle.
Plateau Frustration and Pre-Breakthrough Dips
One of the weirdest emotional phenomena in learning:
You practice hard.
You study.
You apply feedback.
And your performance… drops.
This is the pre-breakthrough dip. It often means:
Your brain is abandoning old, inefficient patterns.
You haven’t yet stabilised the new, better schema.
If you don’t know this is normal, you’ll quit right before the upgrade finishes installing.
The Emotional Cost of Reps
Emotionally, reps get cheaper over time:
Early reps:
Every mistake feels like a referendum on your worth.
“I messed up” = “I am dumb / untalented.”
Later reps:
Mistakes feel like useful data.
You can laugh at them, track them, and iterate.
A big part of mastery isn’t fearlessness; it’s getting so used to feeling stupid that it stops being a big deal.
Identity & Narrative: The “Identity Lag”
One of the strangest phenomena in skill acquisition is Identity Lag.
This occurs when your skills improve faster than your self-image. You might be performing at a professional level, but your internal narrative is still running the “I’m just a beginner learning the ropes” script.
The Impostor Syndrome Trap: This usually peaks at the late-Intermediate stage. You know enough to see how good the real masters are, and you feel like a fraud by comparison. This is actually a good sign—it means your perceptive abilities (taste) have leveled up.
The Shift to Process Identity: Novices identify with the outcome (“I want to win the gold medal”). Masters identify with the process (“I am the type of person who trains every day”). The goal isn’t to write a book; the goal is to be a writer.
Let me repeat the last sentence again:
Masters identify with the process (“I am the type of person who trains every day”). The goal isn’t to write a book; the goal is to be a writer.
After the shift in identity happens, the Second mountain appears.
So you go from “How do I become great?” → “How do I use this to help others, design better systems, or build something that outlives me?”
That’s when mastery stops being only about what you can extract from the skill and starts being about what you can contribute through it.
Behaviour & Practice: How Routines Morph
If you watch a master practice, it looks nothing like a beginner’s practice.
Feature
Beginner Practice
Intermediate Practice
Master Practice
Goal
Accumulate Volume
Fix Weak Spots
Maintain & Innovate
Complexity
Low (Blocked Practice)
Medium (Constraints)
High (Chaos/Simulation)
Mindset
“Don’t mess up.”
“How do I do this?”
“What happens if…?”
Beginner Practice: Maximum Reps, Minimum Complexity
Early on, good practice looks like:
Simple, repetitive drills to accumulate reps.
Low complexity, high frequency.
Safety and playfulness over perfection.
You’re not trying to be clever; you’re trying to get your reps in without frying your brain or your joints.
Examples:
Writers: 200–500 words a day, even if they’re messy.
Coders: tiny scripts, small exercises.
Fighters: basic footwork + jab-cross until it’s boring.
The goal is to feed your nervous system clean, simple, repeated signals.
Intermediate Practice: Deliberate Constraints and Targeted Weak Spots
Intermediate practitioners benefit from deliberate constraints and desirable difficulties:
Drills that isolate weak spots (only left-hand, only under time pressure, only from bad positions).
Using constraints to force creativity (limited tools, limited moves, limited time).
Using feedback tools:
Video review,
Metrics,
Coach critique.
This is where you move from “more reps” to better reps.
Advanced Practice: Micro-Tweaks and High-Stakes Simulation
At advanced levels, the practice zooms in and zooms out:
Zoom in: tiny technical adjustments (angle of wrist, timing of a pause in a story, micro-changes in copy).
Zoom out: high-stakes simulations:
Live performances,
Sparring with killers,
Ship deadlines,
Tournaments and real-world constraints.
Environment & Feedback: From Cheerleaders to Mirrors
The type of feedback you need changes drastically.
Different stages need different kinds of coaching and feedback.
Beginners:
High encouragement, low-stakes reps.
Clear, simple rules: “Do this, not that.”
Minimal nitpicking—too much technical critique kills motivation before the habit of showing up is formed.
Intermediates:
More honest technical critique.
Specific corrections, not vague praise.
Gentle but firm pressure into discomfort: higher speed, tighter deadlines, tougher partners.
Advanced:
Peer-level mirrors and high-quality sparring.
Objective data and performance analysis (metrics, recordings, outcomes).
Coaches who can still see your blind spots without trying to rebuild you from scratch.
You can stagnate for years simply because your feedback is mismatched to your stage.
Peer Groups and “Just-Above-You” People
One of the most powerful accelerators at any stage:
Surrounding yourself with people who are 1–2 levels ahead, not 10.
Why?
People just ahead of you still remember the micro-problems you’re facing.
They can offer specific, recent, actionable moves you can use this week.
Ultra-masters are inspiring, but often too far removed to give step-by-step guidance.
Think of it like climbing:
The person a few metres above you can tell you exactly where the next handhold is.
The person at the summit can tell you the view is amazing… but not which rock to grab next.
All of this—cognition, emotion, identity, practice, environment—is what’s really shifting as you move from Novice to Expert.
Now’s let’s go through the actionable section of the post where we put everything into the action.
Stage-Aware Practice Playbook: Exactly What to Do at Each Phase
If the previous sections were the map of mastery, this section is a practical, stage-aware playbook: what to actually do when you’re a Novice, an Apprentice, or a working Master so your brain, emotions, and environment are all pulling in the same direction.
Phase I – The Novice Actionable Playbook – The Way Out of Novice Hell
Novice Hell feels like this:
Everything is new.
Every attempt is clumsy.
Your brain is overheating and your ego is melting.
The goal at this stage is not to be impressive. The goal is to build a clean foundation of patterns your nervous system can trust.
Writer: intentionally mimic a completely different style for a month to expand your range.
Developer: learn a new paradigm or language that forces you to think differently about architecture.
Fighter: spar lighter but with bizarre constraints (only counter-punching, only body shots) to sharpen specific layers of your game.
You’re not “going backwards”; you’re breaking and rebuilding sub-systems so the overall system can keep evolving.
2. Intuition vs Analysis
At this stage, your intuition is strong but it’s not infallible.
Good Master practice looks like:
Use intuition for rapid diagnosis:
“This play feels wrong.”
“This sentence feels off.”
“This market move smells weird.”
Use analysis to verify and refine:
Review footage, logs, data, or results.
Check whether your hunch was right.
Adjust your internal model accordingly.
This keeps your intuition calibrating instead of calcifying. Mastery isn’t “I always know”; it’s “I can update my knowing fast when reality disagrees.”
Environment
For Masters, environment is everything:
You need peer-level feedback, not just student adoration.
You need advanced coaches who refuse to be impressed and can still see your hidden sloppiness.
You need contexts that expose your limits:
Strong competition,
Unforgiving markets,
High-stakes live settings,
Collaborations with people who scare you a little.
Masters who stagnate usually aren’t “done learning”; they’re overprotected by their current environment.
Stage-aware practice is the cheat code: instead of trying random drills and hoping, you match what you do to where you are.
Next, we’ll zoom in on the darker side of the journey—traps, plateaus, and misdiagnoses—and look at how to recognise when you’re stuck in a stage loop, and how to break out without burning out.
Traps, Plateaus, and Misdiagnosis – How to Diagnose Your Actual Stage (Not Just How You Feel)
One of the most dangerous moments in any skill journey is when your feelings and your actual stage drift apart.
You can feel like a genius and still be on Mount Stupid. You can feel like a fraud and secretly be solidly Proficient.
If you trust vibes alone, you’ll choose the wrong practice, the wrong environment, and the wrong expectations. This section is a reality check: a simple way to diagnose where you actually are, using what you do, how you fail, and how you feel as three lenses.
Don’t ask, “How good do I feel?” Ask, “What does my behaviour, my errors, and my emotional pattern say about my stage?”
Use this diagnostic checklist to objectively locate yourself on the map.
Diagnostic 1: The “Talking While Doing” Test (Cognitive Load)
This is the most reliable test for Fitts & Posner’s stages. It measures available Working Memory.
The Test: Try to perform the skill while holding a conversation or counting backward from 100 by 7s.
If you stop performing to talk: You are in the Novice / Cognitive Stage. Your brain needs 100% of its RAM for the task.
If you slow down or make mistakes: You are in the Apprentice / Associative Stage. You have some automation, but distraction breaks the circuit.
If you can do both easily: You are in the Master / Autonomous Stage. The skill has moved to the basal ganglia; your prefrontal cortex is free.
Diagnostic 2: The Error Signal (Detection Speed)
How long does it take you to realize you messed up?
Novice: You don’t know you made a mistake until the external result is a disaster (e.g., the code crashes, the ball goes into the net). You need a coach to tell you what happened.
Apprentice: You feel the mistake as it happens. You say “damn!” immediately. You know what went wrong, but you couldn’t stop it in time.
Master: You predict the mistake before it happens and micro-correct effortlessly. To an observer, it looks like you never make mistakes.
Diagnostic 3: The Dependency on Rules (Dreyfus Test)
Novice: You crave specific instructions. “Tell me exactly where to put my feet.” You panic if the situation doesn’t fit the rulebook.
Apprentice: You follow the rules but start to see exceptions. “Usually I do X, but in this specific case, I’ll try Y.”
Master: You find rules annoying. You operate on maxims and intuition. If asked why you did something, you might struggle to explain it (“I just felt the opening”).
Summary Checklist: Where Are You?
Signal
Novice (Phase I)
Apprentice (Phase II)
Master (Phase III)
Cognitive Load
“Brain Hell” – 100% focus needed.
“The Grind” – Hard work, high focus.
“Autopilot” – Low effort, high speed.
Primary Emotion
Anxiety / Confusion / Overwhelm
Frustration / Boredom / Determination
Quiet Confidence / Flow / Complacency
Response to Errors
“What just happened?”
“I know what I did wrong.”
“I fixed it before it broke.”
Need for Rules
“Give me the recipe.”
“I’m testing the recipe.”
“I don’t need a recipe.”
The Verdict:
Mostly Novice? Go to Phase I Protocol: Volume + Rules.
Mostly Apprentice? Go to Phase II Protocol: Variability + Feedback.
Mostly Master? Go to Phase III Protocol: Disruption + Simulation.
Designing Your Own Stage Model for Any Skill
Canonical models like Dreyfus and Fitts & Posner are excellent skeletons, but they are not the full body. They are incredible starting points, but they are not built for your messy, specific life as a writer, coder, founder, or martial artist.
They tell you generally what a Novice looks like, but they don’t tell you what a Novice writer looks like compared to a Novice powerlifter.
To truly orient yourself, you need to overlay these universal laws onto your specific domain. You need to move from a generic map of “The Mountain” to a specific topographic map of your mountain; a custom map that fits your domain, your constraints, and your ambitions—so your practice plan is no longer vague inspiration, but an operating manual.
Why You Need a Custom Map
If you rely solely on generic terms like “Intermediate,” you risk getting lost. In coding, “Intermediate” might mean you know the syntax but can’t design a scalable system. In Brazilian Jiu-Jitsu, “Intermediate” might mean you can survive a round but can’t submit a resisting opponent. In business, “Intermediate” might mean you have product-market fit but no operational leverage.
Creating a custom stage map creates Scaffolding. It breaks the intimidating journey into reachable rungs. It allows you to say, “I am not failing at being a Master; I am succeeding at being a Stage 2 Apprentice.”
Step-by-Step: How to Build a Stage Map
Think of this like designing a game with clear levels. Each level needs:
What the player can actually do.
How the level feels.
What kind of training is happening there.
Where players usually get stuck.
Use this four-step framework to build a mastery map for your specific craft.
Step 1: Define Observable Behaviours (The External Reality)
Do not rely on how you feel. Start with behaviour. What can this person actually do?
Pick your skill (say, writing), and for each stage, define concrete, observable markers:
Novice Writer
Needs prompts and templates to start.
Struggles to finish pieces.
Sentences are clunky; ideas aren’t clear even to them.
Apprentice Writer
Can finish drafts consistently.
Can follow a basic structure (intro–body–conclusion).
Sometimes gets positive feedback, sometimes crickets.
Working Master Writer
Consistently produces work that gets results: sign-ups, replies, shares, sales.
Can adapt tone and structure for different contexts without panicking.
Has a recognisable “voice.”
Do the same for coding, martial arts, business—whatever your domain is.
Key rule: If an outside observer couldn’t see it, it doesn’t count as behaviour. aka
Define what a camera would see.
Step 2: Add Emotional and Identity Markers (The Internal Reality)
Next, layer in how each stage feels from the inside and how the person describes themselves. This helps you predict emotional dips.
Ask:
“What’s the emotional vibe here?”
“How does this person talk about themselves and the skill?”
Staying with writing:
Novice Emotional/Identity Markers
Feels: excited + embarrassed, big swings between “maybe I can do this” and “I’m trash.”
Language: “I’m trying to get into writing,” “I want to start a newsletter.”
Apprentice Emotional/Identity Markers
Feels: frustrated, impatient, sometimes bored with drills.
Language: “I’m a writer, but I’m not where I want to be yet,” “I can write, but…”
Working Master Emotional/Identity Markers
Feels: steady confidence, occasional fear of stagnation.
Language: “I write,” full stop. Or, “This is just what I do.”
You’re basically creating a semiotic layer: the words, feelings, and stories attached to each stage. This matters because we live inside stories; identity drives behaviour.
Step 3: Add Practice Patterns and Feedback Needs
Now define what training actually looks like at each stage, and what feedback is most helpful.
Ask:
“What does a typical week of practice look like for someone at this stage?”
“What kind of coaching or feedback helps them most (and what overwhelms them)?”
Example for coding:
Novice Coder
Practice pattern:
Short, frequent sessions.
Mostly guided exercises and tiny projects.
Feedback:
Basic correctness checks.
Positive reinforcement so they don’t quit in week 2.
Specific code review: naming, structure, edge cases.
Help connecting “this bug” to general patterns.
Working Master Coder
Practice pattern:
Large systems, architecture design, refactors.
High-stakes reviews; performance and reliability work.
Feedback:
Peer-level critique.
Data-driven feedback: performance metrics, production incidents, scalability issues.
Once you see the pattern, designing stage-appropriate practice becomes much easier: you stop giving beginner drills to experts and expert problems to beginners.
Step 4: Mark the “Traps” and Plateau Zones
Finally, label where people usually stall, delude themselves, or drop off so you can pre-commit to pushing through.
Ask for each stage:
“Where do people get stuck?”
“What are the classic lies they tell themselves here?”
“What usually makes them quit or loop endlessly?”
Example for entrepreneurship:
Stage 1 Trap (Novice Founder)
Trap: Endless planning and course collecting; never shipping.
Delusion: “Once I learn one more thing, I’ll finally be ready.”
Stage 2 Trap (Apprentice Founder)
Trap: Stuck in the Intermediate Plateau—some revenue, constant chaos.
Delusion: “Because this works now, it’ll keep working forever.”
When you mark these in your stage map, you turn it into a warning system: “I’m in Stage 2, so this frustration is expected. The move isn’t quitting—it’s changing my practice design.”
Visual: The Integrated Mastery Stack
This is the “Grand Unified Theory” of this guide. It compresses the biological, psychological, and practical dimensions into a single dashboard. Print this out.
Stage
Psychological State (4 Stages)
Motor State (Fitts & Posner)
Decision State (Dreyfus)
Neurochemistry (The Fuel)
Practice Protocol (The Action)
1. The Novice
Unconscious Incompetence
(Ignorance/Bliss)
Cognitive
(High verbal effort)
Context-Free Rules
(Follow the recipe)
High Cortisol/NE
(Stress/Alertness)
Blocked Practice
Deconstruction & Repetition
2. The Apprentice
Conscious Incompetence
(Pain/Awareness)
Associative
(Detecting errors)
Situational Aspects
(Noticing nuance)
Norepinephrine & Dopamine
(Frustration & Correction)
Feedback Loops
Tighten error detection speed
3. The Journeyman
Conscious Competence
(Effortful execution)
Associative
(Refining movement)
Goals & Planning
(Strategic choice)
Dopamine (RPE)
(Reward Prediction Error)
Interleaving & Variability
Add noise and constraints
4. The Master
Unconscious Competence
(Autopilot/Flow)
Autonomous
(Low brain load)
Intuitive Grasp
(Tacit knowledge)
Endocannabinoids / Opioids
(Flow State cocktail)
Simulation & Disruption
Break autonomy to improve
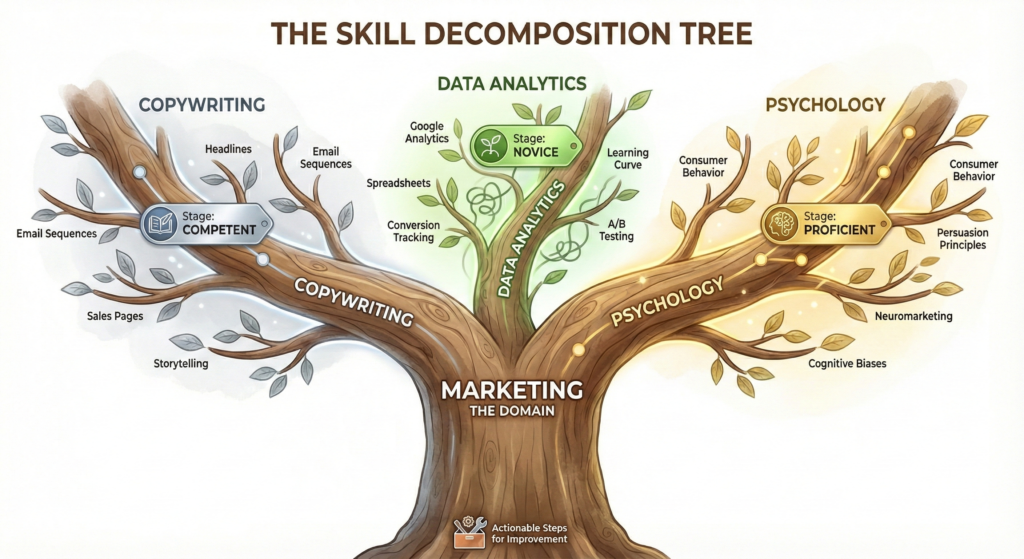
The Skill Decomposition Tree
Now, zoom in further.
Most skills are not one monolithic ability; they’re trees of sub-skills. Your stage can differ across branches.
Example: Writing Decomposition Tree
Idea Generation
Research & Note-Taking
Structure & Outlining
Line-Level Style (words, rhythm, clarity)
Editing & Revision
Publishing & Distribution
Audience/Market Understanding
You might be:
Proficient at idea generation,
Apprentice at structure,
Novice at distribution.
Sketch a Skill Decomposition Tree for your domain, then:
Attach stage labels to each branch (Novice / Apprentice / Master, or your own names).
Notice where your growth bottleneck truly is. Hint: it’s rarely where you’re already strong.
Most people say “I need to get better at X,” when the truth is “I’m a Master in one sub-skill and a Beginner in the one that actually limits my results.”
That’s why do not try to master “Business.” That is too big. Master the sub-skills. Imagine a tree where the trunk is the Domain (e.g., “Marketing”).
Branch 1: Copywriting (Stage: Competent)
Branch 2: Data Analytics (Stage: Novice)
Branch 3: Psychology (Stage: Proficient)
By labeling your stage on each branch, you realize you aren’t “bad at business”; you are just a Novice at Data Analytics. That is a solvable problem.
The Interface: Accelerating Mastery with AI and Modern Tools
In the traditional timeline of mastery, the greatest bottleneck was latency.
If you were a writer in 1990, you wrote a draft, mailed it to an editor, and waited three weeks for feedback. Your brain had already flushed the neural context of why you made those choices by the time the critique arrived. The Reward Prediction Error (RPE) signal—the dopamine spike that tells your brain “don’t do that again”—was severed from the action.
Today, we have Zero-Latency Feedback.
Generative AI is not just a tool for generating content (which actually atrophies skill); it is a tool for generating feedback loops. When used correctly, AI functions as an “Exoskeleton for Metacognition,” allowing you to cycle through the Associative Stage of learning at a velocity that was previously impossible.
Here is how to use modern tools to build a “Cyborg Mastery” stack.
Cyborg Mastery – Collapsing the Feedback Loop
The speed of learning is determined by the speed of the feedback loop.
New Model: Execute $\rightarrow$ Instant Critique $\rightarrow$ Correction. (Zero Latency).
Use LLMs (like ChatGPT, Claude, or Gemini) as a high-fidelity mirror. Do not ask it to do the work; ask it to critique the work.
The “Roast My Work” Protocol:
When you finish a rep (a block of code, an essay intro, a sales pitch), paste it into an LLM with this prompt:
“Act as a Senior. Critique this work based on. Identify my three biggest blind spots. Be ruthless.”
This creates an immediate error signal, triggering the norepinephrine release required for plasticity while the neural trace is still active.
The Socratic AI Tutor – Prompting for Generative Processing
Novices love to ask AI for answers. Masters ask AI for questions.
When you ask AI to explain a concept, you are engaging in passive consumption. Retention is low. To trigger Generative Processing (where your brain builds new connections), you need to be forced to retrieve information.
Here are 3 versions of the Socratic Prompt:
“I am learning. Do not explain it to me. Instead, act as a Socratic Tutor. Quiz me on the core concepts one by one. If I get it wrong, give me a hint, but do not give me the answer. Wait for my response before moving on.”
Or:
“I’m going to explain the Dreyfus model in my own words. Interrupt me whenever I’m vague, wrong, or missing an important piece. Ask follow-up questions like a strict examiner.”
Or:
“Generate 10 questions that test whether I truly understand cognitive load theory—from basic to brutal. Don’t give me the answers until I’ve tried.”
This forces your brain to do the heavy lifting (Active Recall), which strengthens the myelin coating on those specific retrieval pathways.
If mastery is a conversation between your nervous system and reality, AI lets you simulate reality faster and more aggressively—if you let it question you.
Tree of Thoughts & Skill Deconstruction
Earlier, we talked about breaking skills into sub-skills and building your own stage map. AI can act as an on-demand DiSSS engine (Deconstruct, Select, Sequence, Stakes) because it excels at the Tree of Thoughts (ToT) reasoning method
You can literally hand it your ambition and say:
“I want to learn “XXX”. Break this skill down into a dependency tree of its smallest atomic sub-skills. Identify the top 20% of sub-skills that will give me 80% of the competence (The Pareto Principle). Organize them into a sequential roadmap from Novice to Competent.”
Or:
“Here’s a description of my current level in Brazilian jiu-jitsu. Help me deconstruct the game into positions, transitions, submissions, and decision points. Highlight where a blue belt typically stalls and propose constraint drills.”
With this prompt, you’re combining:
Skill decomposition – turning a big, vague goal into atomic units.
You still have to choose which drills to run and actually do the work, but AI removes a huge chunk of the planning overhead. That frees more energy for you to:
Execute reps.
Review footage/data.
Reflect on what’s actually improving.
The more time you spend thinking about practice, the less time you spend in practice. Let AI handle the scaffolding so your brain can handle the struggle.
Simulation & Wargaming: Synthetic Reps
The Associative Stage requires high repetition and high failure rates. In the real world, failure is expensive (you lose the client, you crash the production server). In a simulation, failure is free.
Use AI to create Synthetic Reps—risk-free scenarios where you can practice decision-making.
Negotiation:“Act as a stubborn client who thinks my price is too high. I will try to negotiate with you. Respond realistically to my arguments.”
Crisis Management:“Simulate a server outage scenario. Give me logs and user reports one by one. I will tell you my mitigation steps. Tell me if I succeed or make it worse.”
Language Learning:“Roleplay a waiter in a Parisian café. Only speak French. If I make a grammar mistake, pause the roleplay to correct me, then continue.”
The goal is not to script life. The goal is to compress experience:
10 tough conversations in one evening.
20 sales objections in one sitting.
5 different strategic futures for your business explored in an hour.
When those situations show up in real life, your nervous system has already seen similar patterns. You’ve already felt a version of that pressure. Your “prediction horizon” is longer; your decision speed is faster.
This allows you to compress a year’s worth of “situational aspects” (Dreyfus Model) into a week of intensive simulation.
The Spirit: Identity, Shokunin, and the Infinite Game of Mastery
In an age of binge-watching and info-snacking, mastery is the antithesis of passive consumption. When you craft something, you engage deeply with reality and reshape it.
Philosopher Rassmussen says craftsmanship (shokunin) is done “for its own sake and for the public good”.
Mastery teaches patience, humility, and the dignity of work. It can become a source of flow, pride, and meaning that nothing less immersive offers.
It shifts from what you can do to who you are.
The Shokunin Mindset: The Moral Obligation to Quality
In the West, we tend to view “craft” as a transaction: I build the chair, you pay me for the chair. In Japan, the concept of Shokunin (artisan) implies something far deeper. It suggests a social and spiritual obligation to do one’s best for the general welfare of the people.
Jiro Ono, the sushi master featured in Jiro Dreams of Sushi, embodies this. He does not try to be “creative.” He does not try to expand his business to 50 locations. He stands in the same spot, every day, repeating the same process—massaging the octopus, slicing the fish, pressing the rice—seeking to improve it by a fraction of a percent.
The Novice asks: “How can I finish this quickly?”
The Master asks: “How can I do this beautifully?”
For the Shokunin, the repetition is not a chore; it is a ritual. They have fallen in love with the plateau. They understand that the quality of the work is a reflection of the quality of the self. To produce sloppy work is not just a technical failure; it is a betrayal of one’s character.
Wu-Wei: The Biology of Effortless Action
The Taoist concept of Wu-Wei is often translated as “non-action” or “effortless action.” It sounds mystical, but it maps perfectly to the Autonomous Stage and Transient Hypofrontality.
When a master enters this state, the Prefrontal Cortex (the seat of the self, the inner critic, and the manager) shuts down. The brain stops “trying” and simply “does.”
The archer doesn’t release the arrow; the arrow releases itself.
The jazz pianist doesn’t choose the notes; the fingers find them.
Wu-Wei is the state where skill (myelin), environment (context), and identity (self) align so perfectly that the friction of “deciding” evaporates. You are no longer the pilot of the plane; you are the plane.
The Expert Blind Spot: Why You Need a Map
There is a danger in worshipping the master’s intuition too early.
Masters often suffer from the Expert Blind Spot. Because they have “chunked” their knowledge into high-level schemas, they have literally forgotten what it feels like to be a beginner. They might say, “just feel the music,” forgetting that you first need to learn the C-major scale.
The Trap: Trying to copy the freedom of the master without having built the discipline of the apprentice.
The Solution: Use Stage-Aware Tools. Do not trust your intuition in the Cognitive or Associative stages; it is untrained. Trust the checklist. Trust the algorithm. Trust the Stage-Aware Practice Planner. You earn the right to intuition only after you have paid the price in repetition.
Mastery as an Asymptote
In mathematics, an asymptote is a line that a curve approaches but never quite touches. No matter how far you go, there is always a tiny distance remaining.
Mastery is an asymptote. You will never write the perfect sentence. You will never code the perfect system. You will never fight the perfect match.
The Finite Game: Played to win. The goal is to reach the end (get the belt, get the promotion).
The Infinite Game: Played to keep playing. The goal is to sustain the practice.
The master is not the person who has reached the peak. The master is the person who realizes the peak is an illusion, smiles, and keeps climbing anyway. The joy is not in the arrival; it is in the closing of the distance.